原始视频地址: https://www.youtube.com/watch?v=yMalr0jiOAc
为什么用Agent?
为了解决人工研究效率低、响应慢、难以扩展的问题。研发一个Agent助手,针对的是公司内部的人员,提升效率。
与平常的问答机器人不同,JP摩根面对的人群是富有且挑剔的客户。他们显然使用了一种更保险的做法。
以提高人效的角度来观察,全自动化显然是最方便,最节约成本的。但是保证Agent不出错的成本高昂,而且对用户来说,千篇一律的答案是用户不想看到的。同时,一旦系统出错,对于来说,显然是有损公司形象的,这样一个面向内部员工的Agent系统,显然足够有用、足够高效。
现状的不足

组织(Organization)
- 私人银行,专注于为客户定制多样化的投资产品
- 投资研究团队负责筛选与管理一份全面的投资机会清单
挑战(Challenge)
团队经常收到大量关于投资产品的咨询,需要人工进行调研并整理数据,以便提供全面的答复。
主要问题包括:
- 研究过程依赖人工,耗时较长
- 缺乏深入的产品洞察
- 扩展能力受限(难以规模化)
目标(Goal)
实现投资研究自动化,以提供快速且精准的结果。
未来图景

左侧输入方(提问者):
来自以下角色:
- 产品专家(Product Specialist)
- 客户顾问(Client Advisor)
- 尽职调查专员(Due Diligence Professional)
他们将问题提交给:
中间核心系统:Ask D.A.V.I.D.(一个 AI 驱动的智能助手平台)
右侧输出由多智能体(Agents)完成,包括下列目标:
- 精选回答与产品洞察(Curated Answers & Product Insights)
- 标准化报告与文档输出 (Formatted Reports & Documents)
- 自定义分析与图表可视化 (Custom Analytics & Visuals)
如何构建Agent?
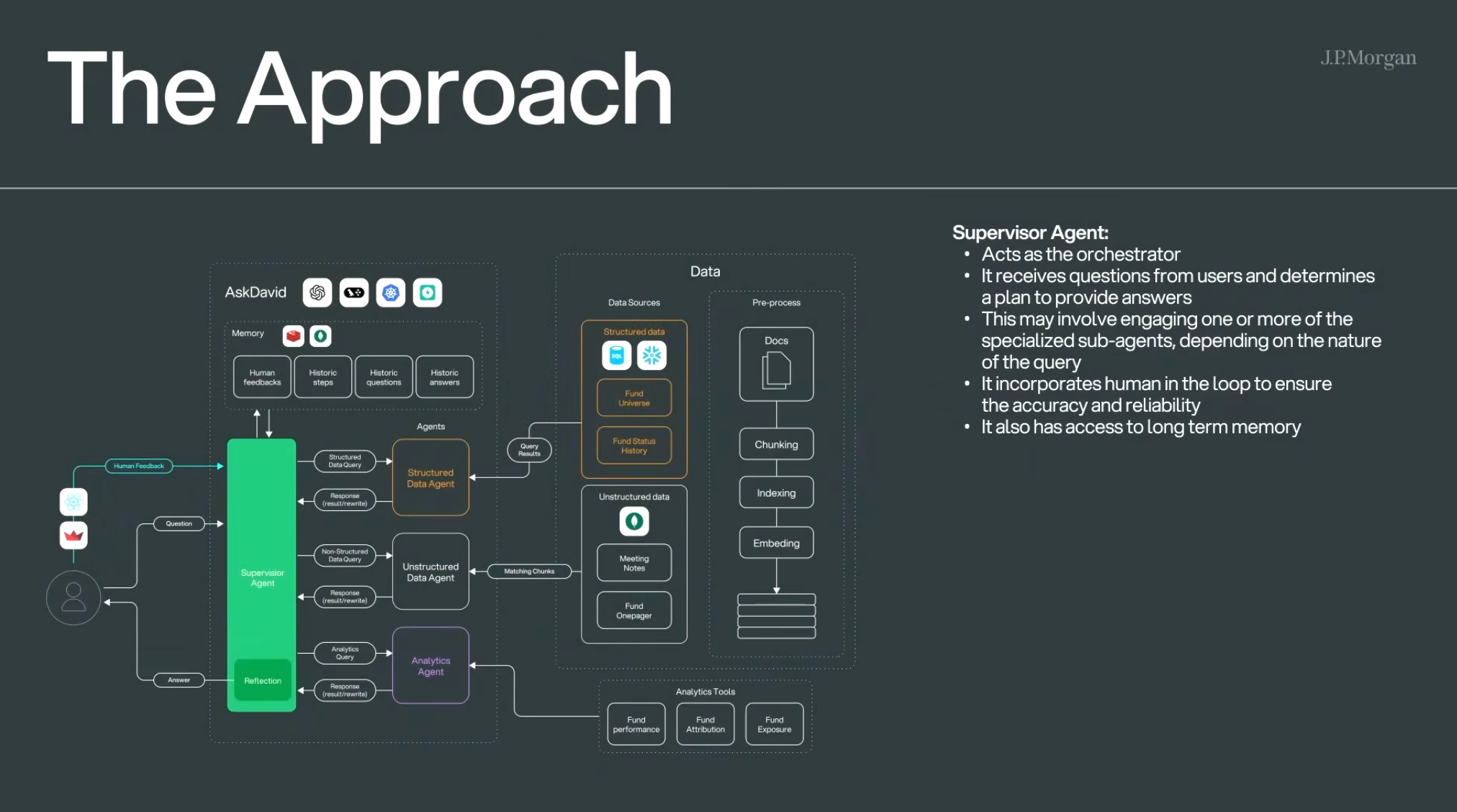
这张图展示了 JP Morgan 的 AI 问答系统 “AskDavid” 的核心架构设计。
它通过一个 Supervisor Agent(协调调度代理) 控制多个子代理(处理结构化/非结构化/分析型问题),从而高效回答用户的投资类问题。
🧠 核心架构:
1. 用户问题入口(左侧)
- 用户提出问题
- 问题进入 Supervisor Agent(协调代理)
- 若系统已有历史记录/人类反馈,会用作参考
2. 核心模块:Supervisor Agent(绿色框)
职责:
- 担任指挥调度者(orchestrator)角色
- 接收用户提问,并制定回答方案
- 可调用一个或多个子代理,视问题类型而定
- 融入 人类审查环节(human-in-the-loop),确保准确性
- 可访问短期及长期记忆(历史步骤、问题、答案等),同时可以定制化用户的喜好
3. 三类子代理(Agents):
| 代理类型 | 功能 | 数据源 |
|---|---|---|
| ✅ Structured Data Agent | 查询结构化数据库(如基金状态),会使用到NL2SQL | Fund Universe, Fund Status History |
| 🟣 Unstructured Data Agent | 检索非结构化内容(如会议纪要) | Meeting Notes, Fund Onepager(可以看到他们用的是MangoDB) |
| 📊 Analytics Agent | 处理分析类查询(如基金表现) | 如Fund Performance, Attribution, Exposure 等工具 |
每个代理查询后返回结果并可能重写答案,交由主代理整合。
4. 数据预处理流程:
- 对文档进行预处理(切分、索引、嵌入)
- 为非结构化代理提供向量化搜索能力
5. 系统记忆(Memory 模块):
包括以下内容,供问答生成时参考:
- 人类反馈(Human feedbacks)
- 历史步骤(Historic steps)
- 历史问题(Historic questions)
- 历史答案(Historic answers)
6. Reflection(反思模块):
系统会在生成答案后进行「反思检查」,增强输出可靠性。
工作流
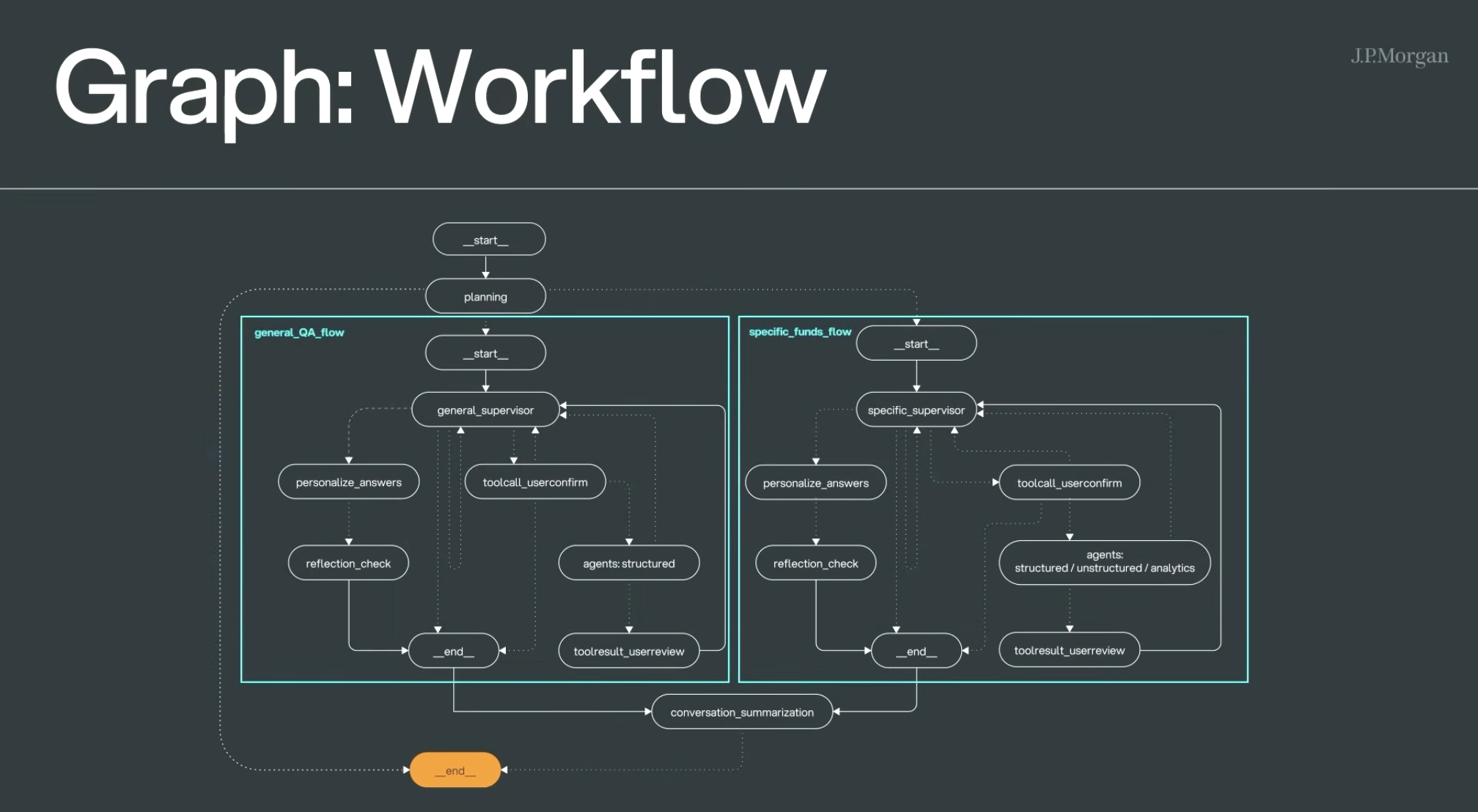
工作流整体采用了两个大的流程:通用QA流和基金专用流。
- 通用QA流回答通用问题,比如"我在当下如何投资黄金?“这类问题。
- 基金专用流回答基金相关
实例:为什么我的某个基金被终止了?
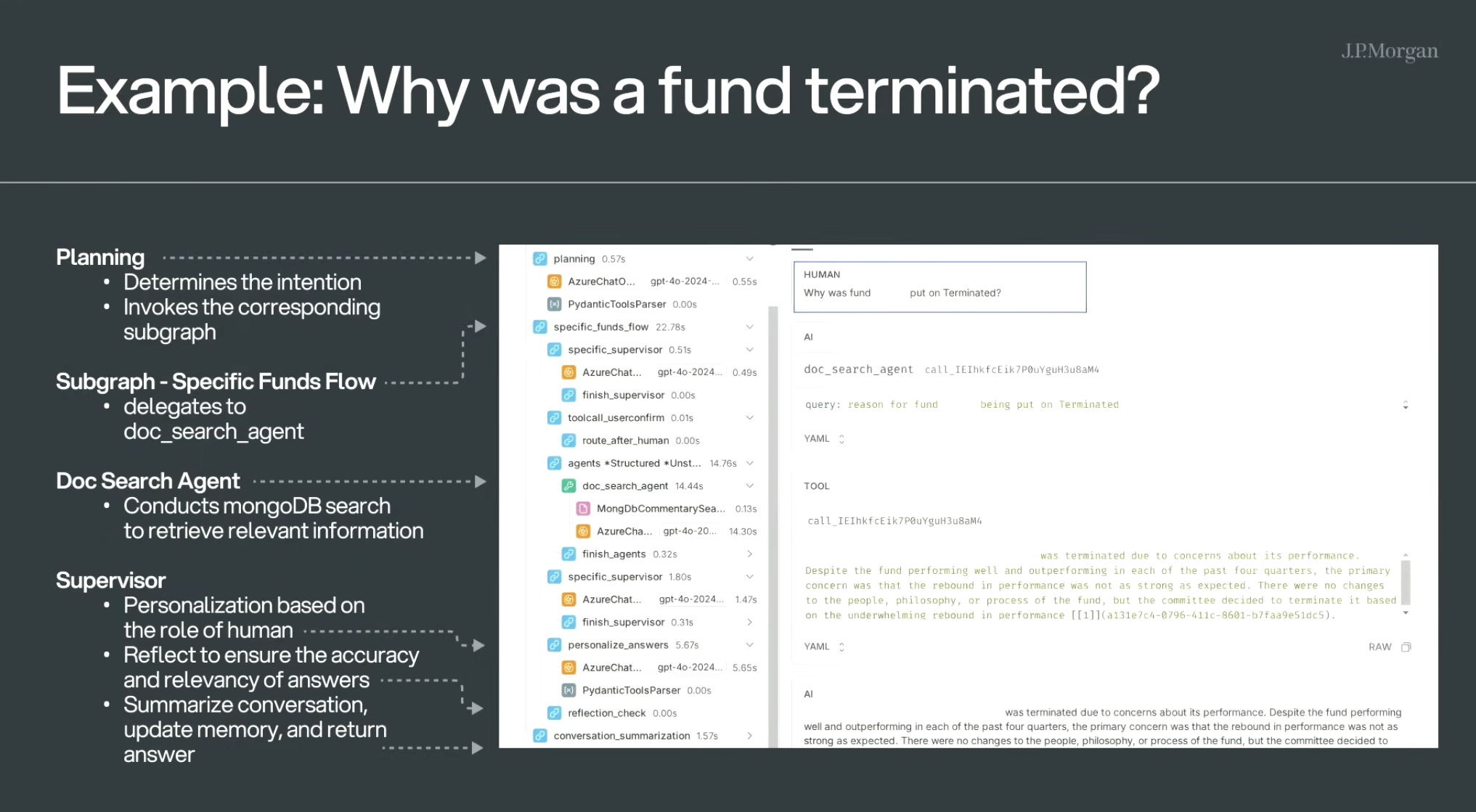
- Planning:识别问题意图,判断走哪个工作流
- Specific Funds Flow:走基金专属流程,调度文档检索代理
- Doc Search Agent:搜索 MongoDB,拿到终止原因原始数据
- Supervisor:
- 个性化处理答案
- 自检答案是否完整、准确
- 总结归档到记忆中
架构迭代中带来的三个启发
1.开始时保持简洁设计,过程中经常重构
罗马不是一天盖成的,JP摩根的团队这个复杂的多Agent系统,也是从最原始的版本,一步步升级迭代来的。
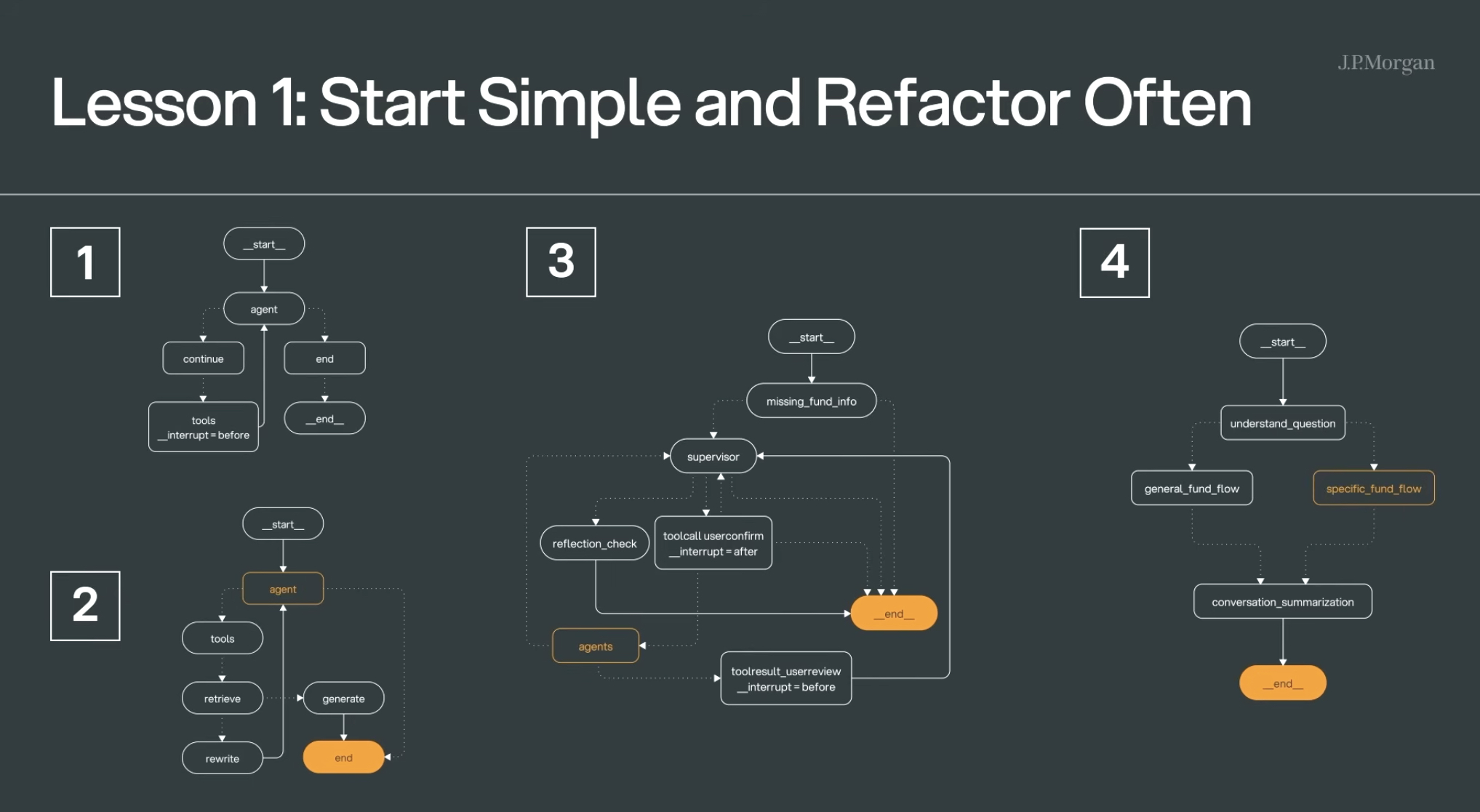
简单的ReAct模型驱动的Agent -> Rag Agent ->单supervisor的Agent系统 -> 双supervisor的Agent系统
2.评估效果驱动开发
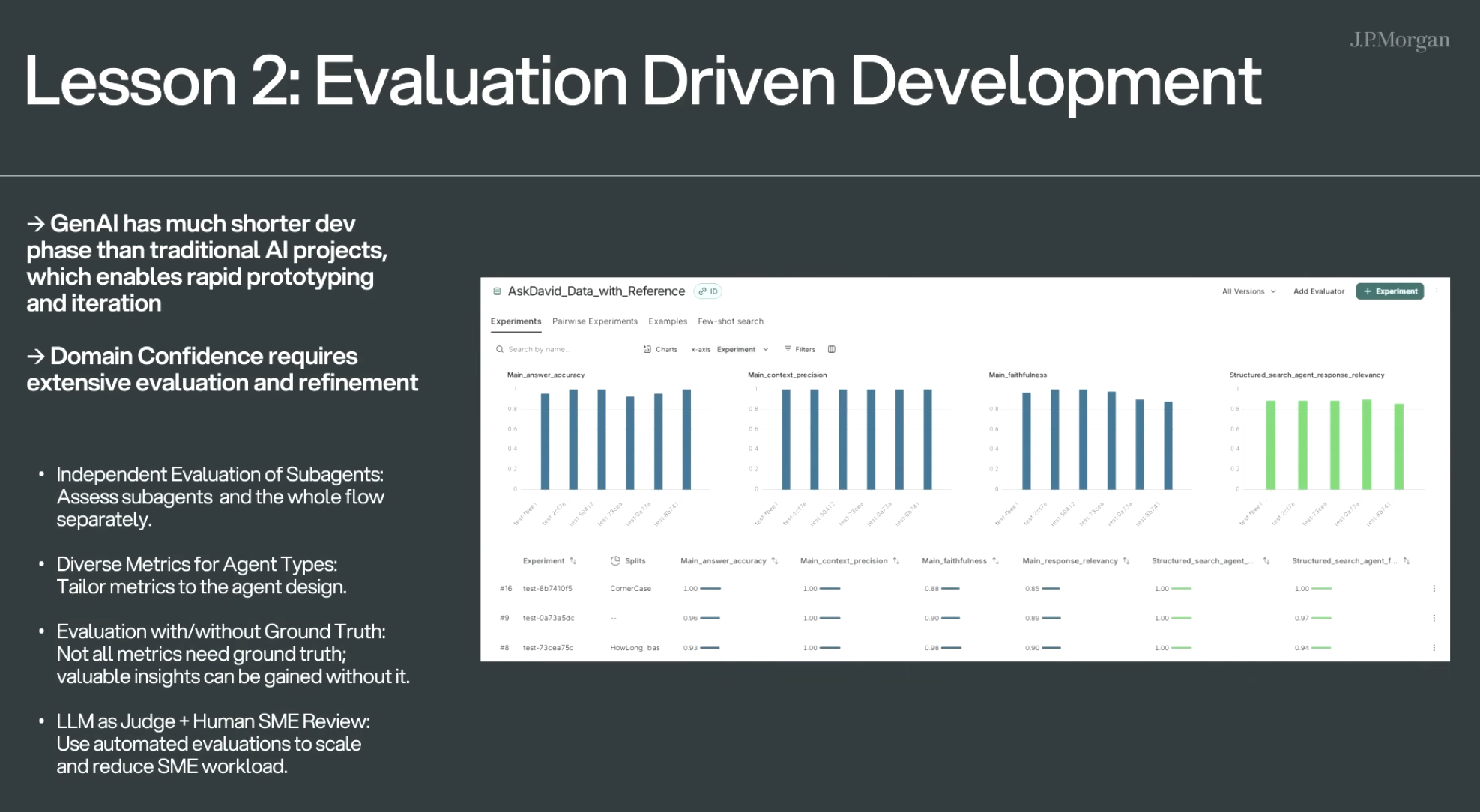
🔹 核心观点:
- 生成式AI的开发周期远短于传统AI项目,这使得快速原型和快速迭代成为可能。
- 在特定业务领域建立信心,需要大量评估与持续优化。
🔹 具体做法:
- 子代理独立评估
分别评估每个子代理(subagent)和整体工作流程。 - 按代理类型定制评估指标
不同类型的代理应使用不同的评估维度(如准确率、忠实度等)。 - 支持有/无标准答案(ground truth)的评估
并非所有评估都需要标准答案,有些情况即使没有也能获得有效洞察。 - 大模型评审 + 人类专家复核
利用LLM自动评审实现规模化,再通过人类专家(SME)审查关键点,减轻人工负担。
3.引入人工专家(SME)参与流程
SME:Subject Matter Expert(领域专家),指在特定领域中具备专业知识的人士。
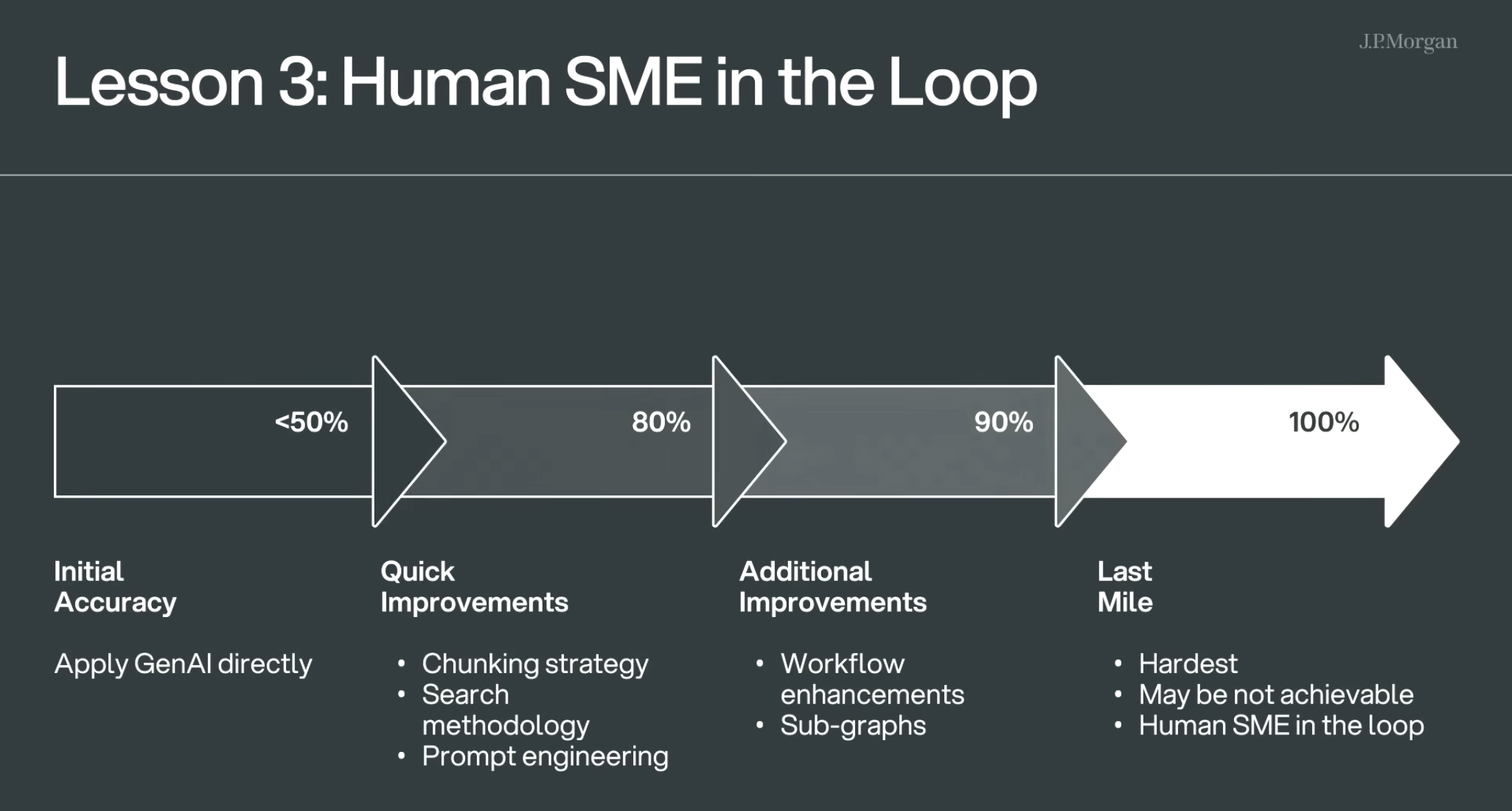
这张图展示了从模型初始到接近完美的优化过程,分为四个阶段:
🎯 初始准确率(Initial Accuracy)< 50%
- 直接使用生成式AI(GenAI)
⚡ 快速提升阶段(Quick Improvements),提升到约 80%
通过以下方式快速改进:
- 文本切块策略(Chunking strategy)
- 搜索方法优化(Search methodology)
- 提示词工程(Prompt engineering)
🔧 进阶优化阶段(Additional Improvements),提升到约 90%
- 工作流增强(Workflow enhancements)
- 子图构建(Sub-graphs)
🧠 最后一公里(Last Mile),目标 100%(但可能无法完全实现)
- 最难的部分
- 可能达不到
- 需要人工专家(SME)参与评估与微调